Olap кубы
Содержание
- Что такое OLAP?
- OLAP-куб:
- Основные аналитические операции OLAP
- Типы систем OLAP
- ROLAP
- MOLAP
- Гибридный OLAP
- Преимущества OLAP
- Недостатки OLAP
- Резюме:
- Хранилища данных (место OLAP в информационной структуре предприятия)
- OLAP — удобный инструмент анализа
- Определение и основные понятия OLAP
- Тест FASMI
- OLAP = многомерное представление = Куб
- «Разрезание» куба
- Метки
- Иерархии и уровни
- Архитектура OLAP-приложений
- Технические аспекты многомерного хранения данных
Что такое OLAP?
Оперативная аналитическая обработка (OLAP) — это категория программного обеспечения, которая позволяет пользователям одновременно анализировать информацию из нескольких систем баз данных. Это технология, которая позволяет аналитикам извлекать и просматривать бизнес-данные с разных точек зрения.
Аналитики часто должны группировать, объединять и объединять данные. Эти операции в реляционных базах данных являются ресурсоемкими. Данные OLAP могут быть предварительно рассчитаны и агрегированы, что ускоряет анализ.
Базы данных OLAP делятся на один или несколько кубов. Кубы разработаны таким образом, что создание и просмотр отчетов становится проще. OLAP означает онлайн-аналитическую обработку.
В этом уроке вы узнаете
- OLAP куб
- Основные аналитические операции OLAP
- Типы систем OLAP
- ROLAP
- MOLAP
- Гибридный OLAP
- Преимущества OLAP
- Недостатки OLAP
OLAP-куб:

В основе концепции OLAP лежит куб OLAP. OLAP-куб — это структура данных, оптимизированная для очень быстрого анализа данных.
Куб OLAP состоит из числовых фактов, называемых мерами, которые классифицируются по измерениям. OLAP Cube также называют гиперкубом .
Обычно операции с данными и анализ выполняются с использованием простой электронной таблицы, где значения данных располагаются в формате строк и столбцов. Это идеально подходит для двумерных данных. Однако OLAP содержит многомерные данные, причем данные обычно получают из другого и несвязанного источника. Использование электронной таблицы не является оптимальным вариантом. Куб может хранить и анализировать многомерные данные в логической и упорядоченной форме.
Как это работает?
Хранилище данных будет извлекать информацию из нескольких источников данных и форматов, таких как текстовые файлы, таблицы Excel, мультимедийные файлы и т. Д.
Извлеченные данные очищаются и преобразуются. Данные загружаются на сервер OLAP (или куб OLAP), где информация предварительно рассчитывается заранее для дальнейшего анализа.
Основные аналитические операции OLAP
Четыре типа аналитических операций в OLAP:
- Свернуть
- Дрель-вниз
- Ломтик и кости
- Поворот (поворот)
1) Свернуть:
Свертывание также известно как «консолидация» или «агрегация». Операция свертки может быть выполнена двумя способами
- Уменьшение размеров
- Восхождение на концепцию иерархии. Иерархия понятий — это система группировки вещей в зависимости от их порядка или уровня.
Рассмотрим следующую диаграмму

- В этом примере города Нью-Джерси и Потерянные Ангелы свернуты в страну США.
- Показатели продаж в Нью-Джерси и Лос-Анджелесе составляют 440 и 1560 соответственно. Они становятся 2000 после свертывания
- В этом процессе агрегирования данные перемещаются вверх по иерархии от города к стране.
- В процессе свертки необходимо удалить хотя бы одно или несколько измерений. В этом примере измерение Quater удалено.
2) Развертка
При детализации данные разбиты на более мелкие части. Это противоположность процесса накопления. Это можно сделать через
- Двигаясь вниз по иерархии понятий
- Увеличение размера

Рассмотрим схему выше
- Квартал Q1 пробурен до месяцев января, февраля и марта. Соответствующие продажи также являются регистрами.
- В этом примере добавляются месяцы измерений.
3) Срез:
Здесь выбрано одно измерение и создан новый вложенный куб.
Следующая диаграмма объясняет, как выполнялась операция среза:

- Время измерения нарезается с Q1 в качестве фильтра.
- Новый куб создан в целом.
Игральная кость:
Эта операция похожа на срез. Разница в кости заключается в том, что вы выбираете 2 или более измерений, которые приводят к созданию вложенного куба.

4) Пивот
В Pivot вы вращаете оси данных, чтобы обеспечить альтернативное представление данных.
В следующем примере сводка основана на типах элементов.

Типы систем OLAP
OLAP Иерархическая структура

| Тип OLAP | объяснение |
| Реляционный OLAP (ROLAP): | ROLAP — это расширенная СУБД вместе с многомерным отображением данных для выполнения стандартной реляционной операции. |
| Многомерный OLAP (MOLAP) | MOLAP Реализует работу в многомерных данных. |
| Гибридная онлайн-аналитическая обработка (HOLAP) | В подходе HOLAP агрегированные итоги хранятся в многомерной базе данных, а подробные данные хранятся в реляционной базе данных. Это обеспечивает как эффективность данных модели ROLAP, так и производительность модели MOLAP. |
| Настольный OLAP (DOLAP) | В Desktop OLAP пользователь загружает часть данных из базы данных локально или со своего рабочего стола и анализирует их.
DOLAP относительно дешевле в развертывании, поскольку предлагает очень мало функций по сравнению с другими системами OLAP. |
| Веб OLAP (WOLAP) | Web OLAP — система OLAP, доступная через веб-браузер. WOLAP — это трехуровневая архитектура. Он состоит из трех компонентов: клиент, промежуточное программное обеспечение и сервер базы данных. |
| Мобильный OLAP: | Мобильный OLAP помогает пользователям получать доступ и анализировать данные OLAP с помощью своих мобильных устройств. |
| Пространственный OLAP: | SOLAP создан для облегчения управления как пространственными, так и непространственными данными в географической информационной системе (ГИС) |
ROLAP
ROLAP работает с данными, которые существуют в реляционной базе данных. Таблицы фактов и измерений хранятся в виде реляционных таблиц. Он также позволяет проводить многомерный анализ данных и является самым быстрорастущим OLAP.
Преимущества модели ROLAP:
- Высокая эффективность данных. Он обеспечивает высокую эффективность данных, поскольку производительность запросов и язык доступа оптимизированы, в частности, для многомерного анализа данных.
- Масштабируемость. Этот тип системы OLAP предлагает масштабируемость для управления большими объемами данных, даже когда данные постоянно увеличиваются.
Недостатки модели ROLAP:
- Спрос на более высокие ресурсы: ROLAP требует высокого использования человеческих, программных и аппаратных ресурсов.
- Совокупные ограничения данных. Инструменты ROLAP используют SQL для всех вычислений совокупных данных. Однако нет никаких ограничений для обработки вычислений.
- Низкая производительность запросов. Производительность запросов в этой модели низкая по сравнению с MOLAP
MOLAP
MOLAP использует многомерные механизмы хранения на основе массива для отображения многомерных представлений данных. В основном они используют куб OLAP.
Узнайте больше об OLAP
Гибридный OLAP
Гибридный OLAP представляет собой смесь как ROLAP, так и MOLAP. Он предлагает быстрое вычисление MOLAP и более высокую масштабируемость ROLAP. HOLAP использует две базы данных.
- Агрегированные или вычисленные данные хранятся в многомерном кубе OLAP
- Подробная информация хранится в реляционной базе данных.
Преимущества гибридного OLAP:
- Этот тип OLAP помогает экономить дисковое пространство, а также остается компактным, что помогает избежать проблем, связанных со скоростью и удобством доступа.
- В Hybrid HOLAP используется технология кубов, которая обеспечивает более высокую производительность для всех типов данных.
- ROLAP мгновенно обновляются, и пользователи HOLAP имеют доступ к этим мгновенно обновляемым данным в реальном времени. MOLAP обеспечивает очистку и преобразование данных, тем самым улучшая актуальность данных. Это приносит лучшее из обоих миров.
Недостатки гибридного OLAP:
- Повышенный уровень сложности . Главный недостаток систем HOLAP заключается в том, что они поддерживают как инструменты, так и приложения ROLAP и MOLAP. Таким образом, это очень сложно.
- Потенциальные совпадения : есть большие шансы перекрытия, особенно в их функциональности.
Преимущества OLAP
- OLAP — это платформа для всех видов бизнеса, включая планирование, составление бюджета, отчетность и анализ.
- Информация и расчеты согласованы в кубе OLAP. Это решающее преимущество.
- Быстро создавать и анализировать сценарии «Что если»
- Простой поиск в базе данных OLAP по широким или конкретным терминам.
- OLAP предоставляет строительные блоки для инструментов бизнес-моделирования, инструментов интеллектуального анализа данных, инструментов отчетности о производительности.
- Позволяет пользователям делать данные куба срезов и кубиков по различным измерениям, мерам и фильтрам.
- Это хорошо для анализа временных рядов.
- Найти некоторые кластеры и выбросы легко с OLAP.
- Это мощная система онлайн-аналитики для визуализации, которая обеспечивает более быстрое время отклика
Недостатки OLAP
- OLAP требует организации данных в схеме звезды или снежинки. Эти схемы сложны в реализации и администрировании.
- Вы не можете иметь большое количество измерений в одном кубе OLAP
- Транзакционные данные не могут быть доступны с помощью системы OLAP.
- Любая модификация в кубе OLAP требует полного обновления куба. Это трудоемкий процесс
Резюме:
- OLAP — это технология, которая позволяет аналитикам извлекать и просматривать бизнес-данные с разных точек зрения.
- В основе концепции OLAP лежит куб OLAP.
- Различные бизнес-приложения и другие операции с данными требуют использования OLAP Cube.
- В OLAP есть пять основных видов аналитических операций: 1) свертывание 2) развертывание 3) срез 4) игральные кости и 5) опора
- Три типа широко используемых систем OLAP — это MOLAP, ROLAP и Hybrid OLAP.
- OLAP для настольных компьютеров, Web OLAP и Mobile OLAP — это некоторые другие типы систем OLAP.
Подавляющее большинство поставщиков OLAP, а их в мире насчитывается около 140, не продают свои компоненты — известны только три компоненты, которые можно купить для собственной разработки. Это Decision Cube компании Inprise в составе компиляторов Delphi и C++ Builder, Pivot Table корпорации Microsoft в составе MS Office, и Dynamic Cube компании Data Dynamic, специализирующейся на разработке OLAP-компонент. Российской компанией «Intersoft Lab» разработана компонента Contour Cube, являющаяся представителем ROLAP-компонент. Она состоит из OLAP-машины, интерфейса доступа к данным, находящимся в SQL-серверах и других источниках, и визуальной части. Компонента обеспечивает лучшие по порядку величины результаты из известных OLAP-компонент. 
Владимир Некрасов Intersoft Lab.
Классификация OLAP — программ
Сначала повторим общеизвестное определение OLAP. OLAP (On Line Analytical Processing) — процесс оперативного анализа — это класс программного обеспечения, предоставляющий пользователю возможность мгновенно, в режиме реального времени получать ответы на произвольные аналитические запросы.
Так сложилось, что не любые программы, которые быстро выполняют произвольные запросы, расчеты и выдают пользователю данные в понятном ему виде принято считать OLAP-средством. К классу OLAP относят только те программы, которые в качестве внешнего интерфейса предоставляют пользователю многомерную управляемую таблицу. Эта таблица позволяет пользователю менять местами колонки и строки, закрывать и раскрывать — описательные колонки, задавать условия фильтрации и при этом она автоматически вычисляет промежуточные в группах данных и окончательные итоги по — цифровым колонкам. Неотъемлемой частью OLAP-анализа является графическое отображение данных.
Программы, реализующие эту методику, делятся на следующие категории:
- OLAP-сервер или MOLAP-многомерная СУБД. Это машина вычислений и многомерная база данных, к которой обращаются клиентские программы с командами на получение данных и выполнение вычислений. В MOLAP хранятся — наборы данных, фактов и измерений, с заранее вычисленными агрегатами.
- MOLAP-компонента. Это инструмент программиста, при помощи которого разрабатываются клиентские программы, получающие вычисленные кубов от OLAP-сервера по какому-либо интерфейсу, например OLE DB for OLAP корпорации Microsoft.
- ROLAP-компонента. Это тоже инструмент программиста. В отличие от визуальной OLAP-компоненты она содержит собственную OLAP-машину для преобразования реляционных данных или многомерной матрицы в многомерные кубы. Другими словами, эта программа по запросу пользователя в оперативной памяти вычисляет агрегаты и сама же их отображает на экране.
- ROLAP-сервер. Относительно новый класс программного обеспечения. В отличие от OLAP-сервера не имеет в своем составе многомерной базы данных, а преобразует данные реляционной СУБД в многомерные кубы по запросу многих клиентских приложений.
- OLAP-программа. Это законченное решение, содержащее в своем составе OLAP-компоненту, средства описания произвольных запросов (Ad-hoc query) и интерфейс доступа к базам данных. В свою очередь такие программы можно разбить на две группы: MOLAP- и ROLAP-программы.
OLAP-компоненты
Любое конечное решение содержит OLAP-компоненту, которая является интерфейсом пользователя. Эти компоненты похожи друг на друга. Их визуальная часть состоит из элементов управления и элементов отображения данных. Как правило, это таблица, в полях которой содержаться данные, а колонки и строки являются элементами управления.
Подавляющее большинство поставщиков OLAP, а их в мире насчитывается около 140, не продают свои компоненты. Нам известно только три компоненты, которые можно купить для собственной разработки. Это Decision Cube компании Inprise в составе компиляторов Delphi и C++ Builder, Pivot Table корпорации Microsoft в составе MS Office, и Dynamic Cube компании Data Dynamic, специализирующейся на разработке OLAP-компонент.
Decision Cube компании Inprise поставляется как VCL-компонента. По нашей классификации относится к ROLAP-компонентам, то есть содержит в своем составе OLAP-машину и предназначен только для работы с реляционными СУБД или локальными таблицами. Он отличается весьма скромными возможностями. Например, в нем нельзя открыть один элемент измерения, или установить фильтр по нескольким измерениям, отобразить несколько фактов одновременно. Производительность компоненты невысока. Пределом является около 4000 записей при 5 измерениях. Компонента отображает в таблице одновременно только один факт. Неприятной особенностью является наличие в исходных текстах нескольких ошибок, в результате чего только высококвалифицированные программисты после исправления этих ошибок могут использовать компоненту в своих разработках. К достоинствам можно отнести простоту применения и освоения компоненты. При правильном использовании и небольших объемах данных продукты на базе этой компоненты могут оказаться полезными и приемлемыми по быстродействию.
Pivot Table корпорации Microsoft поставляется в двух вариантах: как составная часть MS Excel и как Web-компонента. Web-компонента (ActiveX) может быть использована как в браузере, так и собственном Windows-приложении. Pivot Table является одновременно и MOLAP- и ROLAP-компонентой. По протоколу OLE DB for OLAP он может взаимодействовать с многомерной СУБД MS OLAP Server, или другими 70-ю многомерными СУБД, разработчики которых поддержали этот протокол. По протоколу OLE DB Pivot Table может получать данные от реляционной СУБД и выполнять вычисления кубов в памяти. И конечно данные могут быть получены из заданной области таблицы MS Excel. В этом случае его производительность не отличается от производительности Decision Cube. Компонента отображает в таблице одновременно только один факт. Однако инструментарий компоненты шире, чем у Decision Cube — реализована произвольная фильтрация и раскрытие одного элемента измерения. Основным назначением компоненты является создание интерфейсов к OLAP-серверу в рамках концепции Business Intelligent корпорации Microsoft.
Dynamic Cube компании Data Dynamic является классической ROLAP-компонентой. Он поставляется как VCL для программистов Delphi и C++ Builder и как COM для приверженцев компонентной модели. OLAP- машина компоненты весьма мощна. Она с легкостью обрабатывает десятки и чуть медленнее даже сотни тысяч записей. Есть множественная фильтрация, открытие элемента одного измерения, некоторые дополнительные функции. Компонента позволяет отображать в таблице одновременно несколько фактов. Однако эта компонента довольно дорога, особенно впечатляет ее стоимость для профессиональных разработчиков.
Все три описанные выше компоненты по сравнению с готовыми продуктами многих поставщиков имеют весьма скупую функциональность, ограничивающуюся классическими функциями OLAP: drill down, move, rotate и пр. В то же время в некоторых готовых продуктах часто встречается инструментальная панель, наполненная кнопками дополнительных удобных функций. Таких как , и даже кнопками, выполняющими популярные аналитические задачи, например классический маркетинговый анализ 20/80.
Настольные OLAP-программы
Еще недавно поставщики OLAP-серверов продавали свои продукты по таким ценам, что их покупатели должны были быть богаты как арабские шейхи. Так, приобретение Oracle Express обошлось бы в $100 000 за рабочие места двух аналитиков и двух администраторов. Но, даже после выхода на рынок компании Microsoft, которая обрушила цены, предоставив OLAP-сервер бесплатно в составе MS SQL Server, создание Хранилищ данных или витрин данных остается серьезным мероприятием, требующим привлечения профессионального разработчика, администрирования в процессе эксплуатации и других расходов.
Поэтому на рынке появился особый класс продуктов — DOLAP (Desktop OLAP) — настольный OLAP. Это программа, которая устанавливается на каждый персональный компьютер. Она не требует сервера, имеет «нулевое администрирование». Программа позволяет пользователю настроиться на существующие у него базы данных; как правило, при этом создается словарь, скрывающий физическую структуру данных за ее предметным описанием, понятным специалисту. После этого программа выполняет произвольные запросы и результаты их отображает в OLAP-таблице. В этой таблице, в свою очередь, пользователь может манипулировать данными и получать на экране или на бумаге сотни различных отчетов.
По способу получения данных такие программы можно разделить на локальные и корпоративные:
- Локальные манипулируют данными таблицы MS Excel или небольших баз данных типа Access, DBF, Paradox.
- Корпоративные DOLAP имеют доступ к SQL-серверам или многомерным базам данных и, таким образом, тоже делятся на две категории.
Корпоративные DOLAP, предназначенные для анализа данных SQL-серверов позволяют анализировать уже имеющиеся в корпорации данные, хранящиеся в OLTP-системах. Однако вторым их назначением может быть быстрое и дешевое создание Хранилищ или витрин данных, когда программистам организации требуется лишь создать совокупности таблиц типа «звезда» и процедуры загрузки данных. Наиболее трудоемкая часть работы — разработка интерфейсов с многочисленными вариантами пользовательских запросов, интерфейсов и отчетов становится ненужной. Это буквально за несколько часов реализуется в DOLAP-программе. Освоение же такой программы конечным пользователем требует 30 минут.
DOLAP программы поставляются самими разработчиками баз данных, многомерных и реляционных. Это SAS Corporate Reporter, являющийся почти эталонным по удобству и красоте продуктом, Oracle Discovery, комплекс программ MS Pivot Services и Pivot Table и другие. Эти продукты, за исключением программ Microsoft, стоят недешево. Так SAS Corporate Reporter обойдется в $2000 на одного пользователя.
Большая группа программ поставляется в рамках компании «OLAP в массы», которую проводит корпорация Microsoft. Эти программы предназначены для работы с MS OLAP Services. Как правило, они являются улучшенными вариантами Pivot Table и предназначены для использования в рамках MS Office или Web. Это Matryx, Knosys и т.д.
Благодаря простоте, дешевизне и огромной эффективности этот класс продуктов приобрел огромную популярность на Западе. Большие корпорации строят свои Хранилища с распределенным доступом на основе таких программ.
OLAP-продукты компании «Intersoft Lab»
Контур Стандарт
Основным продуктом компании «Intersoft Lab» является большая информационно-управленческая система «Контур Корпорация», построенная по принципам Хранилища данных. Однако в процессе общения с клиентами компании осознала, что далеко не все готовы на инвестиции и организационные мероприятия, связанные с построением серьезного Хранилища данных. Первым шагом на этом пути для многих банков и предприятий мог бы стать OLAP-анализ данных из имеющихся OLTP-систем и собственных аналитических базах данных.
Для этих целей был создан DOLAP-продукт «Контур Стандарт».
Контур Стандарт 1.0 Первая версия системы относилась к классу локальных DOLAP. Средства программы позволяли организовать прямой доступ к dbf- и paradox-файлам. Кроме того, в состав дистрибутивного пакета входил мигратор данных, который помогал собрать в локальные таблицы данные из имеющихся у организации систем.
Контур Стандарт 2.0 В дальнейшем, для расширения мощности продукта в системе «Контур Стандарт» 2.0 был обеспечен и доступ к произвольным SQL-серверам на уровне таблиц и, что не встречается в зарубежных аналогах, хранимых процедур. Это превратило программу в корпоративную информационно-аналитическую систему. Отдельно был реализован интерфейс к системе «Контур Корпорация».
Одновременно для удобства администрирования программа была разделена на две редакции. Редакция «Developer» позволяет IT-специалисту описать источники данных и выборки. При этом создаются семантические словари, которые скрывают от конечного пользователя физический слой и переводят данные на язык предметной области. Редакция «Run-Time» позволяет анализировать данные и выпускать отчеты. Основным способом манипуляции данными является OLAP-компонента, которая позволяет без программирования и специальных навыков создавать необходимые отчеты. Одновременно были созданы и новые виды удобных аналитических инструментов, которые формально не являются OLAP-таблицами, но являются OLAP-средствами по духу, т.е. реализуют on-line анализ, но в другой форме представления данных.
В первых двух версиях применялась ROLAP-компонента Decision Cube компании Inprise. Однако ее невысокая мощность и функциональная упрощенность сдерживала применение программы в банках и организациях для анализа больших объемов данных. Поэтому было принято решение о ее замене. Маркетинговый анализ и ревизия интеллектуальных и производственных мощностей самой компании привели к решению о создании собственной OLAP-компоненты. В результате разработки компоненты, которую назвали Contour Cube, появилась следующая версия программы — «Контур Стандарт» 3.0, которая позволяет обрабатывать выборки данных до миллиона записей и обладает расширенной аналитической функциональностью.
Contour Cube
Компонента Contour Cube компании «Intersoft Lab» является представителем ROLAP-компонент. Она состоит из OLAP-машины, интерфейса доступа к данным, находящимся в SQL-серверах и других источниках, и визуальной части.
Компонента будет реализована в нескольких версиях для различных применений.
Версия VCL для использования в средах Delphi и C++ Builder компании Inprise. В этом случае данные поставляются через стандартный Data Set этих компиляторов. Доступ к источникам обеспечивается как при помощи BDE, так и ADO, поддержанной в последних версиях этих сред.
Версия COM предназначена для разработчиков на Visual Basic, Visual С++ и т.д. Она обеспечивает доступ к данным при помощи ADO. В будущих версиях будет поддержан и доступ к OLAP-серверам через интерфейс OLE DB for OLAP.
Версия ActiveX является Web-компонентой для создания аналитических Интернет-интерфейсов в стиле, предложенном Microsoft.
Версия DHTML состоит из сервера и DHTML-страниц. Она предназначена для создания аналитических Интернет-интерфейсов в среде UNIX, а также для бурно развивающегося рынка мобильных Интернет-устройств.
Основными достоинствами компоненты являются:
- Обработка больших объемов данных.
- Минимальные требования к памяти.
- Расширенная функциональность.
Высокие характеристики компоненты достигнуты за счет уникальной математической модели, созданной специалистами компании.
Создание множества версий компоненты стало возможно благодаря ее многослойной архитектуре. Слой OLAP Engine является относительно независимой частью компоненты. Он реализован как кросс-платформенная библиотека, имеющая API для различных слоев визуализации. Этот API обладает функциями загрузки данных, вычисления срезов многомерного куба и выполнения аналитических и сервисных функций. Сам слой OLAP Engine состоит из машины вычислений и абстрактного многомерного Хранилища данных, которое может сохраняться в виде файла для передачи другим пользователям или длительного использования.
Обработка больших объемов данных
Тесты на персональном компьютере с процессором Intel Celeron 400 и оперативной памятью 64 Мб дали следующие результаты. Загрузка 60 000 записей с 6-ю измерениями занимает 5 секунд; дальнейшие манипуляции, такие как полный поворот таблицы, drill down и drill up выполняются за десятые доли секунды.
Загрузка 500 000 записей с 7-ю измерениями занимает около 30 секунд, поворот такого куба выполняется в среднем за 2.5 секунды.
Это лучшие по порядку величины (sic!) результаты из известных нам OLAP-компонент. Так, Decision Cube и Pivot Table (без использования OLAP Services) требуют десятки секунд для загрузки и поворота таблицы объемом в 4000 записей и 6-ю измерениями. Скорость работы Dynamic Cube ниже, чем у Contour Cube, в среднем на 30% на средних объемах данных и в разы на предельных объемах.
Таким образом, во многих случаях благодаря своей мощности компонента делает необязательным использование OLAP-сервера. Это значительно упрощает процессы внедрения и администрирования корпоративной системы.
Минимальные требования к памяти
В момент работы с данными компонента занимает наименьший объем оперативной памяти по сравнению с одноклассниками. Так при загрузке 40 000 записей Contour Cube потребляет 7 МБ, Decision Cube 15 МБ.
Расширенная функциональность
В компоненте объединены функции лучших OLAP-компонент:
Уникальное свойство компоненты — алгоритм агрегации «Остаток счета». В связи с тем, что в основном OLAP-компоненты предназначаются для анализа продаж и других суммирующих видов анализов, они агрегируют по времени и остатки счетов. Это является ошибкой — остаток счета за квартал не является суммой остатков счета за день, а является остатком за последний день квартала. Реализация этого алгоритма позволяет использовать компоненту для анализа балансов и делает ее полезной не только для экономистов и маркетологов, но и для бухгалтеров.
Для того чтобы при использовании компоненты за минимальное время создавались мощные законченные продукты, в нее встроен набор часто встречающихся в реальной работе аналитических функций. Каждая из этих функций реализована как кнопка в инструментальной панели визуальной части компоненты. Вот перечень этих функций:
- Удалить нулевые колонки, удалить нулевые строки, удалить нулевые колонки и строки. Применяется для сжатия разреженных таблиц.
- Полный поворот. При этом колонки и строки таблицы меняются местами. Применяется для улучшения восприятия таблиц аналитиком, для подбора лучшей печатной формы.
- Фильтр по факту. Позволяет задать абсолютные граничные значения факта или количество наибольших или наименьших элементов. Является одним из инструментов факторного анализа.
- Кластерный анализ. Разбиение данных на заданное количество групп по предельным значениям факта. Например, разбиение клиентов на крупных, средних и мелких по объемам полученных от них доходов.
- 80/20. Популярная на Западе разновидность кластерного анализа в маркетинге. Пример ее применения: показать 20% клиентов, которые приносят 80% прибыли.
- Ранжирование. Генерация нового измерения «место в списке» по значению заданного факта и сортировка по нему. Полезно для анализа избирательных компаний, сравнения банков, предприятий, филиалов по заданному показателю.
- Отображение одновременно нескольких статистических итогов, таких как среднее, среднеквадратическое отклонение и т.д. Эта функция понравится продвинутым специалистам, особенно в области финансового, фондового анализа.
- Выгрузка в форматы MS Excel, MS Word, html. Позволяют продолжить анализ привычными средствами MS Excel, создать отчет произвольной формы, опубликовать отчет в Интернет.
В связи с невозможностью защиты авторских прав в России на программные продукты, физическая защита которых принципиально не реализуема, компонента как коммерческий продукт будет поставляться только на Западный рынок. Однако российские потребители могут воспользоваться ее достоинствами для развития
собственного бизнеса в продуктах «Контур Стандарт» и «Контур Корпорация».
| Обсудить на форуме | Написать автору | Написать вебмастеру |
Михаил Альперович
Что такое OLAP сегодня, в общем-то знает каждый специалист. По крайней мере, понятия «OLAP» и «многомерные данные» устойчиво связаны в нашем сознании. Тем не менее тот факт, что эта тема вновь поднимается, надеюсь, будет одобрен большинством читателей, т. к. для того, чтобы представление о чем-либо с течением времени не устаревало, нужно периодически общаться с умными людьми или читать статьи в хорошем издании…
Хранилища данных (место OLAP в информационной структуре предприятия)
Термин «OLAP» неразрывно связан с термином «хранилище данных» (Data Warehouse).
Приведем определение, сформулированное «отцом-основателем» хранилищ данных Биллом Инмоном: «Хранилище данных — это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений».
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Зачем строить хранилища данных — ведь они содержат заведомо избыточную информацию, которая и так «живет» в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных, хранением их в форматах различных СУБД и в разных «уголках» корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах. Автор имеет достаточно печальный опыт попыток «накормить» голодных аналитиков «сырыми» данными из оперативных систем — им это оказалось «не по зубам».
Таким образом, задача хранилища — предоставить «сырье» для анализа в одном месте и в простой, понятной структуре. Ральф Кимбалл в предисловии к своей книге «The Data Warehouse Toolkit» пишет, что если по прочтении всей книги читатель поймет только одну вещь, а именно: структура хранилища должна быть простой, — автор будет считать свою задачу выполненной.
Есть и еще одна причина, оправдывающая появление отдельного хранилища — сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
На мой взгляд, под хранилищем можно понимать не обязательно гигантское скопление данных — главное, чтобы оно было удобно для анализа. Вообще говоря, для маленьких хранилищ предназначается отдельный термин — Data Marts (киоски данных), но в нашей российской практике его не часто услышишь.
OLAP — удобный инструмент анализа
Централизация и удобное структурирование — это далеко не все, что нужно аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного — гибкости. Их нельзя «покрутить», «развернуть» или «свернуть», чтобы получить желаемое представление данных. Конечно, можно вызвать программиста (если он захочет придти), и он (если не занят) сделает новый отчет достаточно быстро — скажем, в течение часа (пишу и сам не верю — так быстро в жизни не бывает; давайте дадим ему часа три). Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по нескольку в час. И чем больше «срезов» и «разрезов» данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых «срезов». Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Компоненты, входящие в типичное хранилище, представлены на рис. 1.

Рис. 1. Структура хранилища данных
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Подытоживая, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям (чтобы не мешать оперативным пользователям). Но мы тем самым рискуем наступить на уже описанные выше грабли, т. е. начать анализировать оперативные данные, которые напрямую для анализа непригодны.
Определение и основные понятия OLAP
Для начала расшифруем: OLAP — это Online Analytical Processing, т. е. оперативный анализ данных. 12 определяющих принципов OLAP сформулировал в 1993 г. Е. Ф. Кодд — «изобретатель» реляционных БД. Позже его определение было переработано в так называемый тест FASMI, требующий, чтобы OLAP-приложение предоставляло возможности быстрого анализа разделяемой многомерной информации ().
Тест FASMI
Fast (Быстрый) — анализ должен производиться одинаково быстро по всем аспектам информации. Приемлемое время отклика — 5 с или менее.
Analysis (Анализ) — должна быть возможность осуществлять основные типы числового и статистического анализа, предопределенного разработчиком приложения или произвольно определяемого пользователем.
Shared (Разделяемой) — множество пользователей должно иметь доступ к данным, при этом необходимо контролировать доступ к конфиденциальной информации.
Multidimensional (Многомерной) — это основная, наиболее существенная характеристика OLAP.
Information (Информации) — приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
OLAP = многомерное представление = Куб
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей — измерений (Dimensions) — находятся данные, количественно характеризующие процесс — меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п. Пользователь, анализирующий информацию, может «разрезать» куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
В качестве мер в трехмерном кубе, изображенном на рис. 2, использованы суммы продаж, а в качестве измерений — время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины — по странам, а данные о времени совершения операций — по месяцам. Чуть позже мы рассмотрим уровни группировки (иерархии) подробнее.
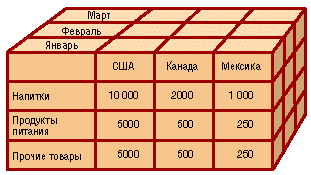
Рис. 2. Пример куба
«Разрезание» куба
Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех? Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки строк и столбцов.
Двумерное представление куба можно получить, «разрезав» его поперек одной или нескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, — и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) — другое, а в ячейках таблицы — значения мер. При этом набор мер фактически рассматривается как одно из измерений — мы либо выбираем для показа одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения), либо показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую — значения единственного «неразрезанного» измерения).

Рис. 3. Двумерный срез куба для одной меры
На рис. 4 представлено лишь одно «неразрезанное» измерение — Store, но зато здесь отображаются значения нескольких мер — Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина).

Рис. 4. Двумерный срез куба для нескольких мер
Двумерное представление куба возможно и тогда, когда «неразрезанными» остаются и более двух измерений. При этом на осях среза (строках и столбцах) будут размещены два или более измерений «разрезаемого» куба — см. рис. 5.

Рис. 5. Двумерный срез куба с несколькими измерениями на одной оси
Метки
Значения, «откладываемые» вдоль измерений, называются членами или метками (members). Метки используются как для «разрезания» куба, так и для ограничения (фильтрации) выбираемых данных — когда в измерении, остающемся «неразрезанным», нас интересуют не все значения, а их подмножество, например три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Иерархии и уровни
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней (levels). Например, метки измерения «Магазин» (Store) естественно объединяются в иерархию с уровнями:
All (Мир)
Country (Страна)
State (Штат)
City (Город)
Store (Магазин).
Архитектура OLAP-приложений
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных. То, как данные хранятся, грубо говоря, не волнует ни конечного пользователя, ни разработчиков инструмента, которым клиент пользуется.
Многомерность в OLAP-приложениях может быть разделена на три уровня:
- Многомерное представление данных — средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными; слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
- Многомерная обработка — средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
- Многомерное хранение — средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третий уровень, хотя и является широко распространенным, не обязателен, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур; процессор многомерных запросов в этом случае транслирует многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД.
Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных, OLAP-клиент (например, Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД, OLAP-сервер (например, Oracle Express Server или Microsoft OLAP Services).
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
Технические аспекты многомерного хранения данных
Как уже говорилось выше, средства OLAP-анализа могут извлекать данные и непосредственно из реляционных систем. Такой подход был более привлекательным в те времена, когда OLAP-серверы отсутствовали в прайс-листах ведущих производителей СУБД. Но сегодня и Oracle, и Informix, и Microsoft предлагают полноценные OLAP-серверы, и даже те IT-менеджеры, которые не любят разводить в своих сетях «зоопарк» из ПО разных производителей, могут купить (точнее, обратиться с соответствующей просьбой к руководству компании) OLAP-сервер той же марки, что и основной сервер баз данных.
OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному. Прежде чем рассмотреть эти способы, нам нужно поговорить о таком важном аспекте, как хранение агрегатов. Дело в том, что в любом хранилище данных — и в обычном, и в многомерном — наряду с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели (агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т. п. Агрегаты хранятся в явном виде с единственной целью — ускорить выполнение запросов. Ведь, с одной стороны, в хранилище накапливается, как правило, очень большой объем данных, а с другой — аналитиков в большинстве случаев интересуют не детальные, а обобщенные показатели. И если каждый раз для вычисления суммы продаж за год пришлось бы суммировать миллионы индивидуальных продаж, скорость, скорее всего, была бы неприемлемой. Поэтому при загрузке данных в многомерную БД вычисляются и сохраняются все суммарные показатели или их часть.
Но, как известно, за все надо платить. И за скорость обработки запросов к суммарным данным приходится платить увеличением объемов данных и времени на их загрузку. Причем увеличение объема может стать буквально катастрофическим — в одном из опубликованных стандартных тестов полный подсчет агрегатов для 10 Мб исходных данных потребовал 2,4 Гб, т. е. данные выросли в 240 раз! Степень «разбухания» данных при вычислении агрегатов зависит от количества измерений куба и структуры этих измерений, т. е. соотношения количества «отцов» и «детей» на разных уровнях измерения. Для решения проблемы хранения агрегатов применяются подчас сложные схемы, позволяющие при вычислении далеко не всех возможных агрегатов достигать значительного повышения производительности выполнения запросов.
Теперь о различных вариантах хранения информации. Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений. Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо многомерное хранение. Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также третий вид — смешанный. Применяются следующие термины:
- MOLAP (Multidimensional OLAP) — и детальные данные, и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
- ROLAP (Relational OLAP) — детальные данные остаются там, где они «жили» изначально — в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
- HOLAP (Hybrid OLAP) — детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от условий — объема данных, мощности реляционной СУБД и т. д.
При хранении данных в многомерных структурах возникает потенциальная проблема «разбухания» за счет хранения пустых значений. Ведь если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть (например, ряд продуктов продается только в небольшом числе регионов), то бо/льшая часть куба будет пустовать, хотя место будет занято. Современные OLAP-продукты умеют справляться с этой проблемой.
Продолжение следует. В дальнейшем мы поговорим о конкретных OLAP-продуктах, выпускаемых ведущими производителями.
С автором статьи можно связаться по адресу: alperovich@digdes.com
Размещено с разрешения редакции PC Week/RE
Оригинал статьи в формате Microsoft Word
| Обсудить на форуме | Написать вебмастеру |
Михаил Альперович PC WEEK/RE (перепечатано с сайта OLAP.Ru)
Что такое OLAP сегодня, в общем-то знает каждый специалист. По крайней мере, понятия «OLAP» и «многомерные данные» устойчиво связаны в нашем сознании. Тем не менее тот факт, что эта тема вновь поднимается, надеюсь, будет одобрен большинством читателей, т. к. для того, чтобы представление о чем-либо с течением времени не устаревало, нужно периодически общаться с умными людьми или читать статьи в хорошем издании…
Хранилища данных (место OLAP в информационной структуре предприятия)
Термин «OLAP» неразрывно связан с термином «хранилище данных» (Data Warehouse).
Приведем определение, сформулированное «отцом-основателем» хранилищ данных Биллом Инмоном: «Хранилище данных — это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений».
Данные в хранилище попадают из оперативных систем (OLTP-систем), которые предназначены для автоматизации бизнес-процессов. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Зачем строить хранилища данных — ведь они содержат заведомо избыточную информацию, которая и так «живет» в базах или файлах оперативных систем? Ответить можно кратко: анализировать данные оперативных систем напрямую невозможно или очень затруднительно. Это объясняется различными причинами, в том числе разрозненностью данных, хранением их в форматах различных СУБД и в разных «уголках» корпоративной сети. Но даже если на предприятии все данные хранятся на центральном сервере БД (что бывает крайне редко), аналитик почти наверняка не разберется в их сложных, подчас запутанных структурах. Автор имеет достаточно печальный опыт попыток «накормить» голодных аналитиков «сырыми» данными из оперативных систем — им это оказалось «не по зубам».
Таким образом, задача хранилища — предоставить «сырье» для анализа в одном месте и в простой, понятной структуре. Ральф Кимбалл в предисловии к своей книге «The Data Warehouse Toolkit» пишет, что если по прочтении всей книги читатель поймет только одну вещь, а именно: структура хранилища должна быть простой, — автор будет считать свою задачу выполненной.
Есть и еще одна причина, оправдывающая появление отдельного хранилища — сложные аналитические запросы к оперативной информации тормозят текущую работу компании, надолго блокируя таблицы и захватывая ресурсы сервера.
На мой взгляд, под хранилищем можно понимать не обязательно гигантское скопление данных — главное, чтобы оно было удобно для анализа. Вообще говоря, для маленьких хранилищ предназначается отдельный термин — Data Marts (киоски данных), но в нашей российской практике его не часто услышишь.
OLAP — удобный инструмент анализа
Централизация и удобное структурирование — это далеко не все, что нужно аналитику. Ему ведь еще требуется инструмент для просмотра, визуализации информации. Традиционные отчеты, даже построенные на основе единого хранилища, лишены одного — гибкости. Их нельзя «покрутить», «развернуть» или «свернуть», чтобы получить желаемое представление данных. Конечно, можно вызвать программиста (если он захочет придти), и он (если не занят) сделает новый отчет достаточно быстро — скажем, в течение часа (пишу и сам не верю — так быстро в жизни не бывает; давайте дадим ему часа три). Получается, что аналитик может проверить за день не более двух идей. А ему (если он хороший аналитик) таких идей может приходить в голову по нескольку в час. И чем больше «срезов» и «разрезов» данных аналитик видит, тем больше у него идей, которые, в свою очередь, для проверки требуют все новых и новых «срезов». Вот бы ему такой инструмент, который позволил бы разворачивать и сворачивать данные просто и удобно! В качестве такого инструмента и выступает OLAP.
Хотя OLAP и не представляет собой необходимый атрибут хранилища данных, он все чаще и чаще применяется для анализа накопленных в этом хранилище сведений.
Компоненты, входящие в типичное хранилище, представлены на рис. 1.
Рис. 1. Структура хранилища данных
Оперативные данные собираются из различных источников, очищаются, интегрируются и складываются в реляционное хранилище. При этом они уже доступны для анализа при помощи различных средств построения отчетов. Затем данные (полностью или частично) подготавливаются для OLAP-анализа. Они могут быть загружены в специальную БД OLAP или оставлены в реляционном хранилище. Важнейшим его элементом являются метаданные, т. е. информация о структуре, размещении и трансформации данных. Благодаря им обеспечивается эффективное взаимодействие различных компонентов хранилища.
Подытоживая, можно определить OLAP как совокупность средств многомерного анализа данных, накопленных в хранилище. Теоретически средства OLAP можно применять и непосредственно к оперативным данным или их точным копиям (чтобы не мешать оперативным пользователям). Но мы тем самым рискуем наступить на уже описанные выше грабли, т. е. начать анализировать оперативные данные, которые напрямую для анализа непригодны.
Определение и основные понятия OLAP
Для начала расшифруем: OLAP — это Online Analytical Processing, т. е. оперативный анализ данных. 12 определяющих принципов OLAP сформулировал в 1993 г. Е. Ф. Кодд — «изобретатель» реляционных БД. Позже его определение было переработано в так называемый тест FASMI, требующий, чтобы OLAP-приложение предоставляло возможности быстрого анализа разделяемой многомерной информации ().
Тест FASMI
Fast (Быстрый) — анализ должен производиться одинаково быстро по всем аспектам информации. Приемлемое время отклика — 5 с или менее.
Analysis (Анализ) — должна быть возможность осуществлять основные типы числового и статистического анализа, предопределенного разработчиком приложения или произвольно определяемого пользователем.
Shared (Разделяемой) — множество пользователей должно иметь доступ к данным, при этом необходимо контролировать доступ к конфиденциальной информации.
Multidimensional (Многомерной) — это основная, наиболее существенная характеристика OLAP.
Information (Информации) — приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
OLAP = многомерное представление = Куб
OLAP предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes). Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар, регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей — измерений (Dimensions) — находятся данные, количественно характеризующие процесс — меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п. Пользователь, анализирующий информацию, может «разрезать» куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
В качестве мер в трехмерном кубе, изображенном на рис. 2, использованы суммы продаж, а в качестве измерений — время, товар и магазин. Измерения представлены на определенных уровнях группировки: товары группируются по категориям, магазины — по странам, а данные о времени совершения операций — по месяцам. Чуть позже мы рассмотрим уровни группировки (иерархии) подробнее.
Рис. 2. Пример куба
«Разрезание» куба
Даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер. Что уж говорить о кубах с количеством измерений, большим трех? Для визуализации данных, хранящихся в кубе, применяются, как правило, привычные двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки строк и столбцов.
Двумерное представление куба можно получить, «разрезав» его поперек одной или нескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, — и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) представлено одно измерение, в вертикальной (заголовки строк) — другое, а в ячейках таблицы — значения мер. При этом набор мер фактически рассматривается как одно из измерений — мы либо выбираем для показа одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения), либо показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую — значения единственного «неразрезанного» измерения).
Рис. 3. Двумерный срез куба для одной меры
На рис. 4 представлено лишь одно «неразрезанное» измерение — Store, но зато здесь отображаются значения нескольких мер — Unit Sales (продано штук), Store Sales (сумма продажи) и Store Cost (расходы магазина).
Рис. 4. Двумерный срез куба для нескольких мер
Двумерное представление куба возможно и тогда, когда «неразрезанными» остаются и более двух измерений. При этом на осях среза (строках и столбцах) будут размещены два или более измерений «разрезаемого» куба — см. рис. 5.
Рис. 5. Двумерный срез куба с несколькими измерениями на одной оси
Метки
Значения, «откладываемые» вдоль измерений, называются членами или метками (members). Метки используются как для «разрезания» куба, так и для ограничения (фильтрации) выбираемых данных — когда в измерении, остающемся «неразрезанным», нас интересуют не все значения, а их подмножество, например три города из нескольких десятков. Значения меток отображаются в двумерном представлении куба как заголовки строк и столбцов.
Иерархии и уровни
Метки могут объединяться в иерархии, состоящие из одного или нескольких уровней (levels). Например, метки измерения «Магазин» (Store) естественно объединяются в иерархию с уровнями:
All (Мир)
Country (Страна)
State (Штат)
City (Город)
Store (Магазин).
Архитектура OLAP-приложений
Все, что говорилось выше про OLAP, по сути, относилось к многомерному представлению данных. То, как данные хранятся, грубо говоря, не волнует ни конечного пользователя, ни разработчиков инструмента, которым клиент пользуется.
Многомерность в OLAP-приложениях может быть разделена на три уровня:
- Многомерное представление данных — средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными; слой многомерного представления абстрагирован от физической структуры данных и воспринимает данные как многомерные.
- Многомерная обработка — средство (язык) формулирования многомерных запросов (традиционный реляционный язык SQL здесь оказывается непригодным) и процессор, умеющий обработать и выполнить такой запрос.
- Многомерное хранение — средства физической организации данных, обеспечивающие эффективное выполнение многомерных запросов.
Первые два уровня в обязательном порядке присутствуют во всех OLAP-средствах. Третий уровень, хотя и является широко распространенным, не обязателен, так как данные для многомерного представления могут извлекаться и из обычных реляционных структур; процессор многомерных запросов в этом случае транслирует многомерные запросы в SQL-запросы, которые выполняются реляционной СУБД.
Конкретные OLAP-продукты, как правило, представляют собой либо средство многомерного представления данных, OLAP-клиент (например, Pivot Tables в Excel 2000 фирмы Microsoft или ProClarity фирмы Knosys), либо многомерную серверную СУБД, OLAP-сервер (например, Oracle Express Server или Microsoft OLAP Services).
Слой многомерной обработки обычно бывает встроен в OLAP-клиент и/или в OLAP-сервер, но может быть выделен в чистом виде, как, например, компонент Pivot Table Service фирмы Microsoft.
Технические аспекты многомерного хранения данных
Как уже говорилось выше, средства OLAP-анализа могут извлекать данные и непосредственно из реляционных систем. Такой подход был более привлекательным в те времена, когда OLAP-серверы отсутствовали в прайс-листах ведущих производителей СУБД. Но сегодня и Oracle, и Informix, и Microsoft предлагают полноценные OLAP-серверы, и даже те IT-менеджеры, которые не любят разводить в своих сетях «зоопарк» из ПО разных производителей, могут купить (точнее, обратиться с соответствующей просьбой к руководству компании) OLAP-сервер той же марки, что и основной сервер баз данных.
OLAP-серверы, или серверы многомерных БД, могут хранить свои многомерные данные по-разному. Прежде чем рассмотреть эти способы, нам нужно поговорить о таком важном аспекте, как хранение агрегатов. Дело в том, что в любом хранилище данных — и в обычном, и в многомерном — наряду с детальными данными, извлекаемыми из оперативных систем, хранятся и суммарные показатели (агрегированные показатели, агрегаты), такие, как суммы объемов продаж по месяцам, по категориям товаров и т. п. Агрегаты хранятся в явном виде с единственной целью — ускорить выполнение запросов. Ведь, с одной стороны, в хранилище накапливается, как правило, очень большой объем данных, а с другой — аналитиков в большинстве случаев интересуют не детальные, а обобщенные показатели. И если каждый раз для вычисления суммы продаж за год пришлось бы суммировать миллионы индивидуальных продаж, скорость, скорее всего, была бы неприемлемой. Поэтому при загрузке данных в многомерную БД вычисляются и сохраняются все суммарные показатели или их часть.
Но, как известно, за все надо платить. И за скорость обработки запросов к суммарным данным приходится платить увеличением объемов данных и времени на их загрузку. Причем увеличение объема может стать буквально катастрофическим — в одном из опубликованных стандартных тестов полный подсчет агрегатов для 10 Мб исходных данных потребовал 2,4 Гб, т. е. данные выросли в 240 раз! Степень «разбухания» данных при вычислении агрегатов зависит от количества измерений куба и структуры этих измерений, т. е. соотношения количества «отцов» и «детей» на разных уровнях измерения. Для решения проблемы хранения агрегатов применяются подчас сложные схемы, позволяющие при вычислении далеко не всех возможных агрегатов достигать значительного повышения производительности выполнения запросов.
Теперь о различных вариантах хранения информации. Как детальные данные, так и агрегаты могут храниться либо в реляционных, либо в многомерных структурах. Многомерное хранение позволяет обращаться с данными как с многомерным массивом, благодаря чему обеспечиваются одинаково быстрые вычисления суммарных показателей и различные многомерные преобразования по любому из измерений. Некоторое время назад OLAP-продукты поддерживали либо реляционное, либо многомерное хранение. Сегодня, как правило, один и тот же продукт обеспечивает оба этих вида хранения, а также третий вид — смешанный. Применяются следующие термины:
- MOLAP (Multidimensional OLAP) — и детальные данные, и агрегаты хранятся в многомерной БД. В этом случае получается наибольшая избыточность, так как многомерные данные полностью содержат реляционные.
- ROLAP (Relational OLAP) — детальные данные остаются там, где они «жили» изначально — в реляционной БД; агрегаты хранятся в той же БД в специально созданных служебных таблицах.
- HOLAP (Hybrid OLAP) — детальные данные остаются на месте (в реляционной БД), а агрегаты хранятся в многомерной БД.
Каждый из этих способов имеет свои преимущества и недостатки и должен применяться в зависимости от условий — объема данных, мощности реляционной СУБД и т. д.
При хранении данных в многомерных структурах возникает потенциальная проблема «разбухания» за счет хранения пустых значений. Ведь если в многомерном массиве зарезервировано место под все возможные комбинации меток измерений, а реально заполнена лишь малая часть (например, ряд продуктов продается только в небольшом числе регионов), то бо/льшая часть куба будет пустовать, хотя место будет занято. Современные OLAP-продукты умеют справляться с этой проблемой.
Продолжение следует. В дальнейшем мы поговорим о конкретных OLAP-продуктах, выпускаемых ведущими производителями.
С автором статьи можно связаться по адресу: alperovich@digdes.com
Версия для печати





